This post will take you to a basic understanding of concepts of simple feature extraction methods in Natural Language Processing.
Need of Such Models to check similarity between sentences
Machine learning algorithms cannot work with the raw data directly the text must be converted into numbers. Especially, vectors of numbers
Bag of Words (BOW)
The Bag-of-words model (BoW ) is the simplest way of extracting features from the text. BoW converts text into the matrix of occurrence of words within a document. This model concerns whether given words occurred or not in the document.
The bag-of-words model is simple to understand and implement and has seen great success in problems such as language modeling and document classification.
Bag of Words involves two steps:
Example: If we are given 4 reviews for veg Italian pizza
Review 1: This pizza is very tasty and affordable.
Review 2: This pizza is not tasty and is affordable.
Review 3: This pizza is delicious and cheap.
Review 4: pizza is tasty and pasta tastes good.
Now if we count the number of unique words in all four reviews we will be getting a total of 12 unique words. Below are the 12 unique words :
- ‘This’
- ‘pizza’
- ‘is’
- ‘very’
- ‘tasty’
- ‘and’
- ‘affordable’
- ‘not’
- ‘delicious’
- ‘cheap’
- ‘tastes’
- ‘good’
2. Measure of the presence of words and plotting: Now if we take Review4 and plot the count of each word in the table below
Review 4: pizza is tasty and pasta tastes good.
| This | pizza | is | very | tasty | and | affordable | not | delicious | cheap | tastes | good |
| 0 | 2 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 |
Drawbacks of using a Bag-of-Words (BoW) Model
- If the new sentences contain new words, then our vocabulary size would increase, and thereby, the length of the vectors would increase too.
- We are retaining no information on the grammar of the sentences nor on the ordering of the words in the text.
TF-IDF:
tf–idf or TFIDF, short for term frequency-inverse document frequency, is a numerical statistic that is intended to reflect how important a word is to a document in a collection or corpus.The tf–idf value increases proportionally to the number of times a word appears in the document and is offset by the number of documents in the corpus that contain the word, which helps to adjust for the fact that some words appear more frequently in general.
· Counts. Count the number of times each word appears in a document.
· Frequencies. Calculate the frequency that each word appears in a document out of all the words in the document.
Term Frequency :
Term frequency (TF) is used in connection with information retrieval and shows how frequently an expression (term, word) occurs in a document. Term frequency indicates the significance of a particular term within the overall document. It is the number of times a word occurs in a review.
TF can be said as what is the probability of finding a word in a document (review).
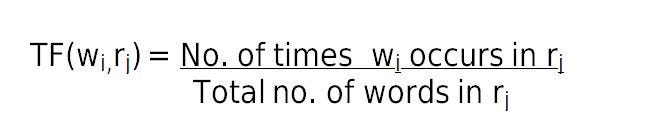
The inverse document frequency is a measure of how much information the word provides, i.e., if it’s common or rare across all documents. It is used to calculate the weight of rare words across all documents in the corpus. The words that occur rarely in the corpus have a high IDF score. It is the logarithmically scaled inverse fraction of the documents that contain the word (obtained by dividing the total number of documents by the number of documents containing the term, and then taking the logarithm of that quotient):
Term frequency–Inverse document frequency
TF–IDF is calculated as:


A high weight in tf–idf is reached by a high term frequency (in the given document) and a low document frequency of the term in the whole collection of documents; the weights hence tend to filter out common terms. Since the ratio inside the IDF's log function is always greater than or equal to 1, the value of IDF (and tf–idf) is greater than or equal to 0. As a term appears in more documents, the ratio inside the logarithm approaches 1, bringing the IDF and tf–idf closer to 0.
TF-IDF gives larger values for less frequent words in the document corpus. TF-IDF value is high when both IDF and TF values are high i.e the word is rare in the whole document but frequent in a document.
TF-IDF also doesn’t take the semantic meaning of the words.
Let’s take an example to get a clearer understanding.
Sentence 1: The car is driven on the road.
Sentence 2: The truck is driven on the highway.
In this example, each sentence is a separate document.
We will now calculate the TF-IDF for the above two documents, which represent our corpus.
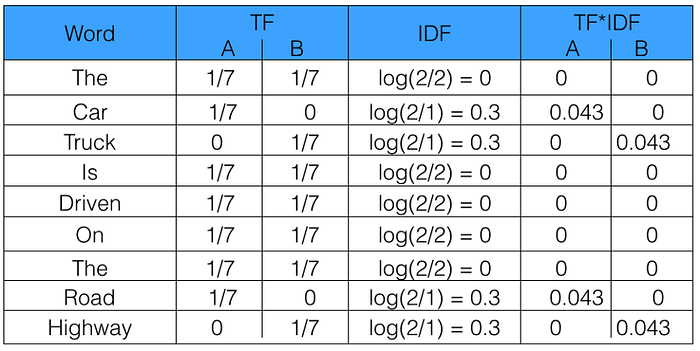
Reviewing-
TFIDF is the product of the TF and IDF scores of the term.
TF = number of times the term appears in the doc/total number of words in the doc
IDF = ln(number of docs/number docs the term appears in)
Higher the TFIDF score, the rarer the term is and vice-versa.
TFIDF is successfully used by search engines like Google, as a ranking factor for content.
The whole idea is to weigh down the frequent terms while scaling up the rare ones.
Code for TF-IDF:

Word2Vec :
Word2Vec model is used for learning vector representations of words called “word embeddings”. This is typically done as a preprocessing step, after which the learned vectors are fed into a discriminative model (typically an RNN) to generate predictions and perform all sorts of interesting things. It takes the semantic meaning of words. I would include this Word2Vec in my next blog in an exhaustive manner.
Comments
Post a Comment